
Theremino ECG
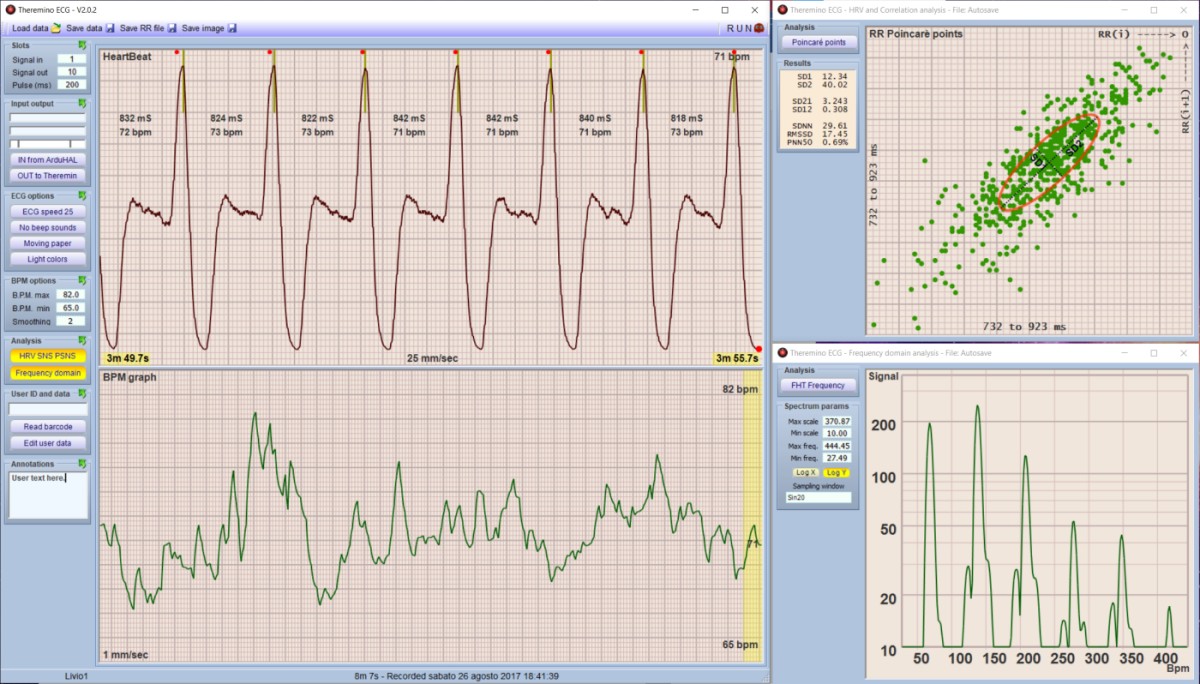
Questa applicazione visualizza e registra i tracciati della frequenza cardiaca. Non è un sostituto dei visualizzatori ECG, ma una applicazione specifica per evidenziare la variazioni di frequenza e le aritmie. Quindi si analizza una sola derivazione e si utilizzano due speciali grafici che non sono presenti negli ECG classici. Il primo mostra le variazioni di frequenza nel tempo e il secondo evidenzia le aritmie mostrando la correlazione del segnale con se stesso spostato nel tempo.
In questo video di YouTube si può vedere la versione originale (2017) della applicazione in funzione.
Questo nuovo video di YouTube mostra la nuova versione che stiamo pubblicando (febbraio 2023).
Per misurare la saturazione dell’ossigeno esistono comodi misuratori portatili che si possono acquistare su eBay per una decina di euro (vedere questa pagina). Abbiamo quindi ottimizzato il sistema per essere semplice e dare il massimo delle prestazioni nella ricerca delle aritmie, un campo che non è coperto da nessun apparecchio commerciale (sia misuratori di saturazione che ECG classici). Per la saturazione avremmo dovuto complicare notevolmente il sensore con due emettitori a diverse lunghezze d’onda.
Nuova versione 2.x
La nuova versione contiene notevoli miglioramenti. Manteniamo ancora le istruzioni e i collegamenti della versione precedente, ma consigliamo di utilizzare al loro posto la nuova documentazione che si scarica da qui:
![]() File di documentazione in italiano
File di documentazione in italiano
Theremino_ECG_Help_ITA.pdf
![]() English documentation file
English documentation file
Theremino_ECG_Help_ENG.pdf
![]() 中文文档文件
中文文档文件
Theremino_ECG_Help_CHN.pdf
![]()
![]()
![]() Documenti originali in formato ODT
Documenti originali in formato ODT
Theremino_ECG_Help_OpenOfficeDocs.zip
Download di Theremino ECG – Versione 2.1
Theremino_ECG_V2.1
Theremino_ECG_V2.1_WithSources (versione per programmatori)
Per tutti i sistemi Windows a 32 e 64 bit. Per Raspberry Pi, Linux, Android e OSX, leggere le note di installazione.
Versioni precedenti della applicazione ECG
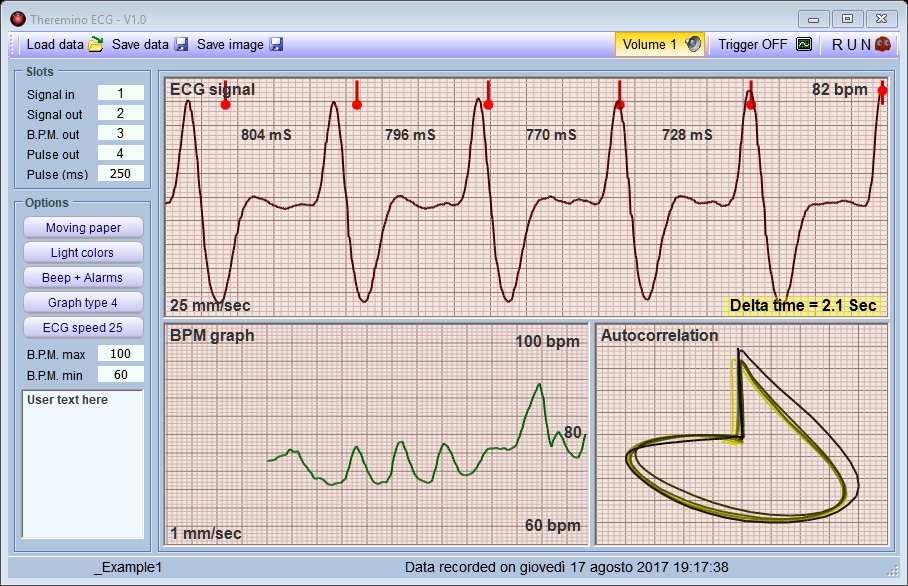
Le versioni precedenti alla 2.x non eseguivano l’HRV per cui dopo aver registrato i dati li si dovevano analizzare con altri programmi, ad esempio con gli HRV (Heart Rate Variability) che presentiamo nel prossimo capitolo di questa pagina.
La documentazione delle versioni precedenti era qui sul sito ma è stata inserita nei PDF della nuova versione che negli aspetti fondamentali è abbastanza simile.
– – – – – – –
Note per le versioni
Versione 1.0: Prima versione pubblicata ma è già completa e ben collaudata.
Versione 1.1
– La barra inferiore ora mostra anche il tempo della parte registrata.
– Lo scorrerimento all’inditro è limitato alla parte registrata.
Versione 1.2
– Eliminato errore con valori di ingresso molto grandi.
– Dopo RUN-STOP il grafico ECG visualizza i dati fino alla fine.
– Partendo con RUN abilitato il DeltaTime viene correttamente azzerato.
Versione 1.3
– Aggiunto il colore verde e rosso nella status bar per indicare quando gli impulsi sono validi.
– Lo Slot PulseOut si attiva solo quando gli impulsi sono validi (da MinBPM a MaxBpm).
– Migliorata la stabilità del grafico BPM.
Versione 1.4
– Il grafico BPM viene memorizzato anche quando si superano il minimo e il massimo della scala visibile.
Download di Theremino ECG – Versione 1.4
Theremino_ECG_V1.4
Theremino_ECG_V1.4_WithSources (versione per programmatori)
Per tutti i sistemi Windows a 32 e 64 bit. Per Raspberry Pi, Linux, Android e OSX, leggere le note di installazione.
 HRV – Heart Rate Variability
HRV – Heart Rate Variability
I file prodotti dalla applicazione Theremino ECG sono compatibili con tutti i software di analisi e in particolare con quelli per le analisi HRV.
Dopo averne provati molti consigliamo Kubios, ma fidatevi non gli stiamo facendo pubblicità, non lo facciamo mai! In questo sito non accettiamo pubblicità, e anche quando ce la offrono diciamo di no! La fiducia dei lettori è più importante dei soldi.
Consigliamo Kubios perché ha una versione gratuita veramente completa. Inoltre abbiamo provato che legge i nostri file senza problemi e ricorda anche le cartelle. Così è possibile recuperare le analisi e visualizzarle di nuovo facilmente. Comunque se preferite potete utilizzare altri programmi per HRV, ad esempio HRVAS, EasieRR, RHRV ecc.. Alcuni sono anche Open Source e tutti leggono facilmente i nostri file di dati.
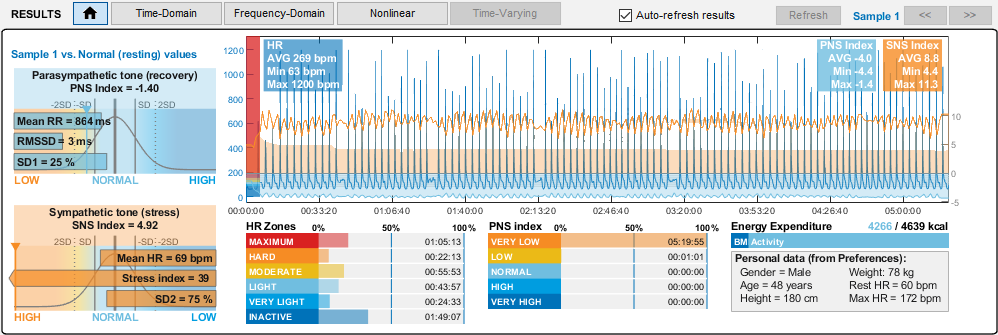
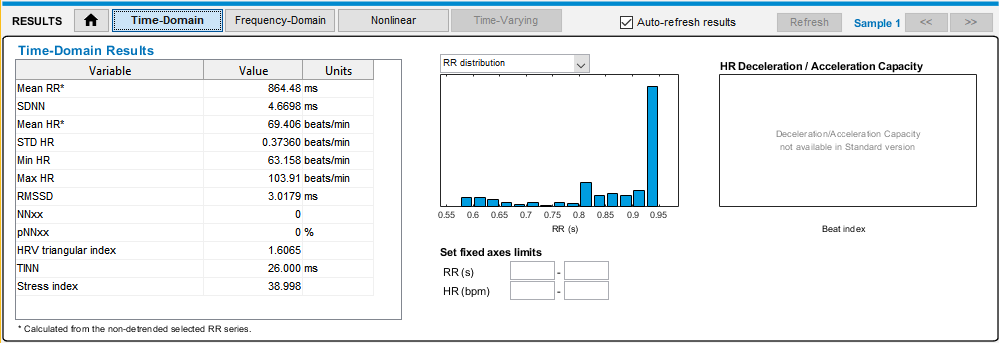
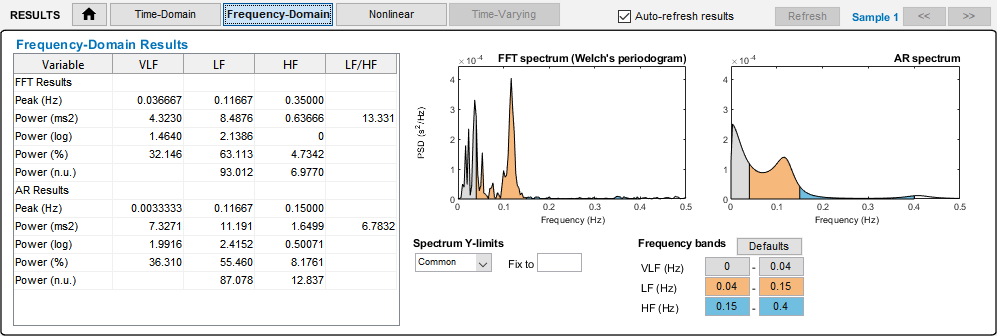
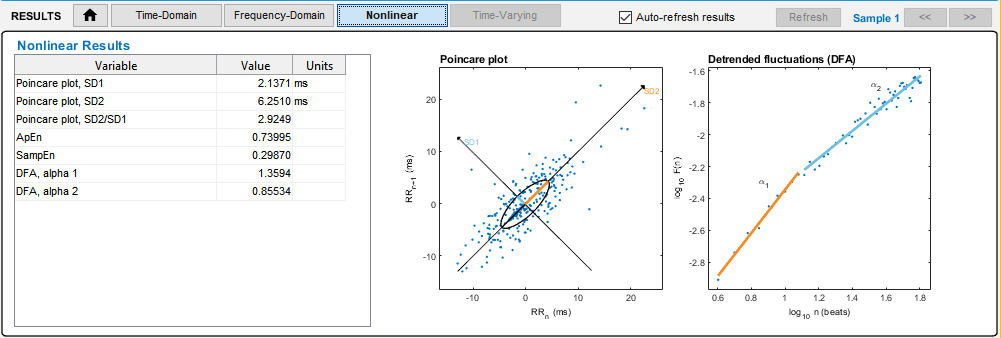
Nella immagine qui a destra si vede il pannello di Kubios che apre un file di dati della applicazione Theremino ECG.
Nelle prossime immagini si vedono i tipi di analisi che si possono fare, ma c’è anche molto di più di quello che si vede qui. Leggete la guida per l’utente per imparare a valutare i risultati e per esplorare tutte le possibilità di analisi.
Scaricare e installare Kubios
La versione gratuita si trova in questa pagina.
Per installarla fate il download della ultima versione di HRV STANDARD da questa pagina.
Poi per attivarla dovete farvi spedire un codice via mail da questa pagina.
Questa applicazione pronuncia il valore numerico di uno Slot e dispone di opzioni per limitare il numero di messaggi alle sole variazioni significative.
In molte occasioni può essere utile conoscere i valori numerici, ad esempio misurati da una bilancia o da altri sensori, senza dover guardare lo schermo per leggerli.
La conversione da testo in voce è di buona qualità e l’utilizzo è immediato. In Windows 10 sono già presenti una o due voci, solitamente quella della propria lingua e l’inglese, per cui la applicazione funziona subito, senza nessuna installazione.
Istruzioni per la finestra superiore (voci installate)
Questa applicazione utilizza le voci già installate nel sistema operativo e messe a disposizione da “System.Speech.Synthesis”.
Non si utilizzano i linguaggi SAPI, ma solo quelli installati e utilizzati dal sistema operativo. Si possono installare nuove lingue in Windows 10, e alcune lingue forniscono nuove voci, oltre a “Elsa”, “Zira”, “David” e “Huhui”, che si vedono nella immagine iniziale. Invece gran parte dei linguaggi che si scaricano da Internet e si installano, non sono validi e non appariranno nella lista di questa applicazione.
Istruzioni per i comandi
- Nella casella “Slot to speech” si scrive il numero dello Slot, da cui leggere i numeri che verranno pronunciati.
- Nella casella “Round to digits” si scrive il numero di cifre significative cui arrotondare il numero. Diminuendo il numero di cifre significative si semplifica il numero da pronunciare e si riduce anche la frequenza dei messaggi vocali.
- La casella “Min change” stabilisce di quanto deve variare il numero per attivare il messaggio. Alzando il valore di questa casella si riduce la frequenza dei messaggi.
- La casella “Min time” stabilisce quanto tempo deve essere passato dal messaggio precedente per attivare un nuovo messaggio. Alzando questo tempo si riduce ulteriormente la frequenza dei messaggi.
- Nella parte destra si trovano due cursori orizzontali. Quello in alto regola la velocità e quello in basso il volume.
Note per le versioni
Versione 1.2 – Prima versione pubblicata.
Download di Theremino SlotsToSpeech – Versione 1.2
Theremino_SlotsToSpeech_V1.2
Theremino_SlotsToSpeech_V1.2_WithSources
Per tutti i sistemi Windows a 32 e 64 bit. Per Raspberry Pi, Linux, Android e OSX, leggere le note di installazione.
Questa applicazione è simile alla precedente (guardate le sue istruzioni) ma legge stringhe di testo dagli SlotText al posto che numeri degli Slot numerici.
Le nuove applicazioni utilizzano anche gli SlotText se ne hanno la necessità. Attualmente (primi mesi del 2022) le altre applicazioni che utilizzano gli SlotText sono:
– Theremino_VideoColors
– Theremino_Cobot
– Theremino_Automation
Comandi verso questa applicazione
I comandi vengono decodificati quando il testo inizia con “COMMAND:”
COMMAND:STOP
COMMAND:SPEED -10 to +10
COMMAND:VOLUME 0 to 100
COMMAND:VOICE ITA F / ENG M / ENG F
Note per le versioni
Versione 1.0 – Prima versione pubblicata.
Versione 1.1 – Aggiunti i comandi per stop, velocità, volume e voce.
Download di Theremino SlotTextToSpeech – Versione 1.1
Theremino_SlotTextToSpeech_V1.1
Theremino_SlotTextToSpeech_V1.1_WithSources
Per tutti i sistemi Windows a 32 e 64 bit. Per Raspberry Pi, Linux, Android e OSX, leggere le note di installazione.
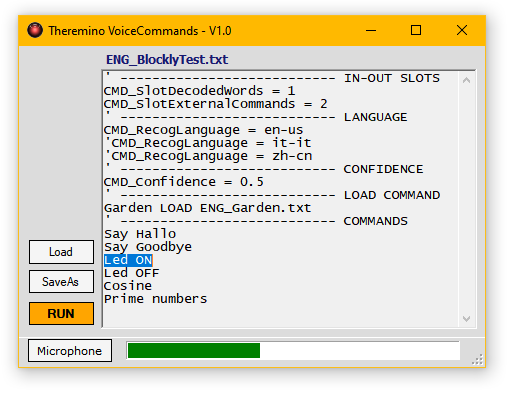 Questa è una applicazione piccola ma molto importante. Con essa si inviano comandi vocali ad altre applicazioni del nostro sistema, un po’ come fa Alexa, ma con la grande differenza che Alexa ha i comandi che vuole lei, mentre noi possiamo scrivere facilmente i comandi e utilizzare le parole che preferiamo.
Questa è una applicazione piccola ma molto importante. Con essa si inviano comandi vocali ad altre applicazioni del nostro sistema, un po’ come fa Alexa, ma con la grande differenza che Alexa ha i comandi che vuole lei, mentre noi possiamo scrivere facilmente i comandi e utilizzare le parole che preferiamo.
Una importante innovazione rispetto ad Alexa, Google e simili, è la possibilità di utilizzare menu con poche voci e di cambiarli con un comando vocale. Questo permette di utilizzare un gran numero di parole e nel contempo minimizzare il pericolo di falsi riconoscimenti in caso di parole simili. Per fare un esempio, se si utilizza la parola GARAGE poi le uniche parole che verranno riconosciute potrebbero essere APRI / CHIUDI / ACCENDI / SPEGNI, senza pericolo di confonderle con parole simili utilizzate per altri ambienti.
Sono disponibili ventisei linguaggi per il riconoscimento vocale. E non è necessario “registrarsi” e dare il proprio indirizzo di mail e nemmeno essere collegati a Internet.
Questa applicazione è più facile da utilizzare della Theremino_Voice spiegata nella prossima pagina. Se eravate già abituati a usare Theremino_Voice fate attenzione che qui si utilizzano comandi simili ma semplificati e con importanti differenze.
La grande novità rispetto alla Theremino_Voice è che i comandi vengono inviati attraverso i nuovi SlotText e quindi ricevuti e utilizzati da altre applicazioni.
Solitamente i comandi verranno ricevuti da Theremino_Automation o Theremino_Blockly, che eventualmente possono anche usare i metodi Text To Speech per rispondere con la voce.
Il riconoscimento (se si parla vicino al microfono) è quasi perfetto e indipendente dalla pronuncia e dalla voce di chi parla. Il metodo di riconoscimento usato è “Speaker Independent” per cui non sono necessarie lunghe e noiose sessioni di apprendimento. Un vantaggio collaterale di questo metodo è che tutti i componenti della famiglia possono parlare al PC ed essere riconosciuti.
Istruzioni per installare i linguaggi
Questa applicazione necessita del “Server runtime” e di almeno una voce SR (Speech Recognition) nella propria lingua. Nella cartella “Installers” ci sono le istruzioni e i link ai file da scaricare e installare.
Si possono installare più lingue e sceglierle con le righe che si trovano nella prima parte del programma.
Ecco alcuni esempi:
CMD_RecogLanguage = en-us
CMD_RecogLanguage = it-it
CMD_RecogLanguage = zh-cn
Prime righe del programma con i comandi
- CMD_SlotDecodedWords = 1 Un numero da 1 a 999 che indica lo Slot di testo cui inviare le parole riconosciute.
- CMD_SlotExternalCommands = 2 Un numero da 1 a 999 che indica lo Slot di testo da cui ricevere i comandi esterni. Per disabilitare i comandi esterni scrivere -1 )
- CMD_RecogLanguage = en-us La lingua sa utilizzare per il riconoscimento, ad esempio en-us, it-it, zh-cn, ecc…)
- CMD_Confidence = 0.7 Scrivere valori da 0.1 a 0.9. Con numeri alti il riconoscimento è più difficoltoso e si deve parlare più vicino al microfono e con maggiore con precisione. Con numeri bassi il riconoscimento è facilitato ma gli errori sono più frequenti. In mancanza di questo comando viene utilizzato il valore 0.6
Istruzioni per le righe delle parole da riconoscere
- All’inizio di ogni riga c’è la parola (o le parole) da riconoscere. Se si vogliono utilizzare più parole, ad esempio Aspiratore acceso le si separano con spazi.
- Le parole riconosciute vengono inviate allo slot di testo specificato con la apposita istruzione di comando: CMD_SlotDecodedWords
- A destra della parola, o delle parole, da riconoscere si possono aggiungere commenti precedendoli con un apice singolo.
- Se a destra della parola da riconoscere si scrive Load seguito dal nome di un file esistente nella cartella Recog_Files, questo file verrà caricato al posto di quello attuale. In questo modo si possono costruire complesse sequenze di menu e sotto-menu, con poche parole da riconoscere. I menu con poche parole rendono più affidabile il riconoscimento.
Comandi esterni
- Per abilitare i comandi esterni si utilizza l’struzione CMD_SlotExternalCommands spiegata prima.
- I comandi esterni sono:
RUN Avvia il riconoscimento vocale.
STOP Ferma il riconoscimento vocale.
LOAD FileName.txt Carica un file differente (che deve essere presente nella cartella Recog_Files) - Questi comandi non fanno differenza tra lettere maiuscole o minuscole.
Pulsanti della parte sinistra
- Load Apre la cartella Recog_Files per caricare un altro programma.
- SaveAs Salva il testo attualmente visibile con un nuovo nome.
- RUN Abilitando questo pulsante (in arancione) il riconoscimento viene avviato.
Controlli della barra inferiore
- Microphone Apre il pannello di regolazione di proprietà del microfono.
- Indicatore del segnale audio – Se questa barra orizzontale è visibile allora il riconoscimento è abilitato e si può parlare. La quantità di segnale audio viene indicata dal riempimento in verde.
Download di Theremino VoiceCommands – Versione 1.0
Theremino_VoiceCommands_V1.0
Theremino_VoiceCommands_V1.0_WithSources
Per tutti i sistemi Windows a 32 e 64 bit. Per Raspberry Pi, Linux, Android e OSX, leggere le note di installazione.
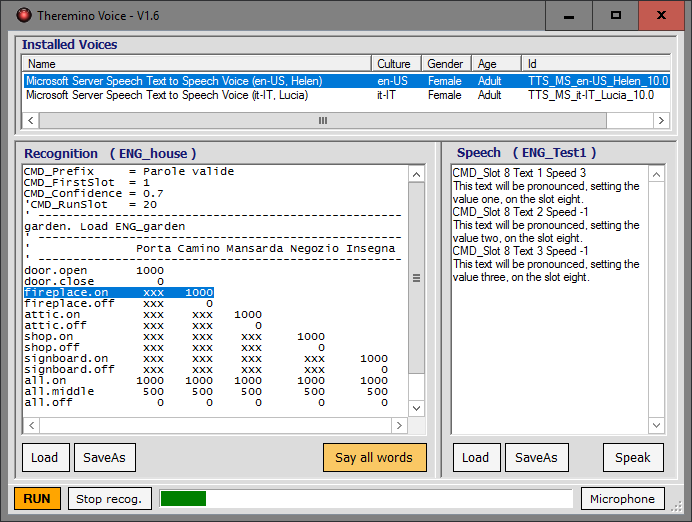
Questa è una applicazione piccola, ma molto importante. Con essa il sistema Theremino può anche ascoltare e parlare. Si possono inviare comandi vocali, ascoltare messaggi di conferma e farsi leggere brani di testo.
La conversione da testo in voce è di buona qualità. Il riconoscimento (se si parla vicino al microfono) è quasi perfetto e indipendente dalla pronuncia e dalla voce di chi parla. Il metodo di riconoscimento usato è “Speaker Independent” per cui non sono necessarie lunghe e noiose sessioni di apprendimento. Un vantaggio collaterale di questo metodo è che tutti i componenti della famiglia possono parlare al PC ed essere riconosciuti.
Sono disponibili ventisei linguaggi, italiano compreso, sia per il parlato, che per il riconoscimento vocale. E non è necessario “registrarsi” e dare il proprio indirizzo di mail e nemmeno essere collegati a Internet.
Una importante innovazione rispetto ad Alexa, Google e simili, è la possibilità di utilizzare menu con poche voci e di cambiarli con un comando vocale. Questo permette di utilizzare un gran numero di parole e nel contempo minimizzare il pericolo di falsi riconoscimenti in caso di parole simili. Per fare un esempio, se si utilizza la parola GARAGE poi le uniche parole che verranno riconosciute potrebbero essere APRI / CHIUDI / ACCENDI / SPEGNI, senza pericolo di confonderle con parole simili utilizzate per altri ambienti.
L’utente stesso può configurare le liste di parole valide e può usare i comandi vocali per caricare altre liste. In questo modo si possono costruire strutture complesse di Menu e Sotto-Menu e controllare qualunque dispositivo, nonché altre applicazioni del sistema Theremino, attraverso gli Slot.
Si potrebbe, ad esempio, telefonare a casa e dire:
- “Serra” e la risposta sarebbe: “OK Serra. Comandi validi: Acqua, Lampade, Aspiratore”
- “Aspiratore” e la risposta sarebbe: “OK Aspiratore. Comandi validi: Acceso, Spento”
- “Acceso” e la risposta sarebbe: “OK Acceso”
Istruzioni per la finestra superiore (linguaggi installati)
Nella finestra superiore vengono mostrati solo i linguaggi TTS (Text To Speech) installati. Attenzione che per ognuno di essi si deve aver installato anche il corrispondente linguaggio SR (Speech Recognition), altrimenti il riconoscimento di quella lingua non funzionerà.
E’ possibile installare più lingue (ognuna composta da due file) e sceglierle nella finestra orizzontale in alto. La lingua che si sceglie, deve corrispondere alla lingua delle parole da riconoscere e da pronunciare, altrimenti la qualità del riconoscimento e della pronuncia sarà pessima.
Si devono installare il “Server runtime” e le voci nella propria lingua. Nella cartella “Installers” ci sono le istruzioni e i link.
AGGIORNAMENTO DEL 2021
ATTENZIONE
Microsoft ha eliminato le pagine con i file delle voci da scaricare.
Per cui scaricate questo file ZIP e scompattatelo dove vi viene più comodo.
https://www.theremino.com/uploads/Theremino_Voice_Installers.zip
Poi installate la Speech Platform, seguendo queste istruzioni:
1) Lanciare sempre “SpeechPlatformRuntime32.msi” (sempre a 32 bit anche se il sistema è a 64 bit)
2) Premere “Next”.
3) Fare doppio click sul file e installarlo.
Infine installate i linguaggi nelle lingue desiderate (sempre a coppie di file SR e TTS).
Ad esempio per installare italiano e inglese (USA) lanciate i file seguenti:
MSSpeech_SR_it-IT_TELE.msi
MSSpeech_TTS_it-IT_Lucia.msi
MSSpeech_SR_en-US_TELE.msi
MSSpeech_TTS_en-US_Helen.msi
Istruzioni per la finestra di sinistra (riconoscimento)
- All’inizio di ogni riga c’è la parola (o le parole) da riconoscere. Se si vogliono utilizzare più parole, ad esempio “Aspiratore Acceso” non le si devono separare con spazi ma con un punto, quindi si scriverà così: “Aspiratore.Acceso”.
- A destra della parola da riconoscere ci sono dei numeri. Sono i numeri che verranno scritti negli Slot, a partire dal primo Slot, quando la parola viene riconosciuta.
- Il numero di Slot interessati dipende da quanti numeri si scrivono nella linea. Possono essere uno solo o anche decine. Quindi, per esempio, se la riga è “verde 0 1000 0”, quando viene riconosciuta la parola “verde”, nei primi tre Slot vengono scritti i valori “zero”, “mille” e “zero”.
- Se al posto di numeri si scrivono delle “x” allora lo slot corrispondente non viene modificato.
- Se si scrive “pulse” allora viene emesso un impulso e poi lo Slot viene subito riportato a zero. Il valore numerico da assegnare allo slot durante l’impulso si scrive immediatamente dopo alla parola “pulse” senza spazi in mezzo. Quindi “pulse1000” vuol dire “invia allo Slot il valore 1000 e rimettilo a zero dopo un breve tempo”.
- Se a destra della parola da riconoscere si scrive “Load” seguito dal nome di un file esistente nella cartella “Recog_Files”, questo file verrà caricato al posto di quello attuale nella finestra di sinistra (riconoscimento). In questo modo si possono costruire complesse sequenze di menu e sotto-menu, con poche parole da riconoscere. I menu con poche parole rendono più affidabile il riconoscimento.
- Se a destra della parola da riconoscere si scrive “LoadTTS” seguito dal nome di un file esistente nella cartella “Speech_Files”, questo file verrà caricato al posto di quello attualmente presente nella finestra di destra.
Comandi per la finestra di sinistra (riconoscimento)
- CMD_Prefix = Parole valide (Le parole da pronunciare come prefisso)
- CMD_FirstSlot = 1 (Il primo slot da utilizzare per questo file)
- CMD_Confidence = 0.7 (Scrivere valori da 0.1 a 0.9. Con numeri alti il riconoscimento è più difficoltoso e si deve parlare più vicino al microfono e con maggiore con precisione. Con numeri bassi il riconoscimento è facilitato ma gli errori sono più frequenti. In mancanza di questo comando viene utilizzato il valore 0.6)
- CMD_RunSlot = 20 (Lo Slot di comando per abilitare, disabilitare il pulsante RUN, in mancanza di questo comando o impostando “-1” il pulsante RUN è solo manuale)
Pulsanti della finestra di sinistra (riconoscimento)
- Load Carica uno dei testi manualmente.
- SaveAs Salva il testo attualmente visibile con un nuovo nome.
- Say nothing / Say one word / Say all words – Con “Say nothing” il riconoscimento non risponde mai. Con “Say one word” si ha come risposta la sola parola riconosciuta. Con “Say all words” la risposta comprende la parola riconosciuta e tutte le parole valide del file attualmente caricato.
Istruzioni per la finestra di destra (lettura del testo)
- Nella finestra di destra ci sono le frasi da pronunciare.
- Ogni frase può risiedere su più righe. All’inizio di ogni frase (o brano) ci deve essere una riga di comando, ad esempio “CMD_Slot 8 Text 2 Speed 1”. Questo comando specifica lo Slot (8), quale numero deve essere scritto in tale slot per far partire la frase (2) e la velocità di pronuncia (1). Le velocità possono essere da -10 (lentissima) a +10 (velocissima).
- Per far pronunciare una di queste frasi un’altra applicazione deve scrivere il numero della frase nello Slot specificato.
- Quando si scrive “0” nello Slot si “riarma” il meccanismo. Poi si scrive un numero e la frase corrispondente viene pronunciata.
Comandi per la finestra di destra (lettura del testo)
Esempi:
- CMD_Slot 1 Text 1 Speed 5 La riga che segue questo comando verrà pronunciata quando sullo Slot 1 si imposta il valore 1. La velocità di pronuncia è molto rapida.
- CMD_Slot 1 Text 2 Speed 1 La riga che segue questo comando verrà pronunciata quando sullo Slot 1 si imposta il valore 1. La velocità di pronuncia è normale.
- CMD_Slot 1 Text 3 Speed -5 La riga che segue questo comando verrà pronunciata quando sullo Slot 1 si imposta il valore 1. La velocità di pronuncia è molto lenta.
Pulsanti della finestra di destra (lettura del testo)
- Load – Carica uno dei testi manualmente.
- SaveAs – Salva il testo attualmente visibile con un nuovo nome.
- Speak – Pronuncia la frase su cui si trova il cursore, oppure tutto il testo selezionato.
- Pause 1.7 – Questo comando produce una pausa nella lettura del testo. Il numero rappresenta il tempo di pausa in secondi e frazioni di secondo.
Pulsanti della barra inferiore
- RUN – Abilitando questo pulsante (in arancione) il riconoscimento viene avviato.
- Stop recog – Abilitando questo pulsante (in arancione) il riconoscimento viene disabilitato quando il computer parla.
- Indicatore del segnale audio – Quando è visibile il riconoscimento è abilitato, si può parlare e la quantità di segnale viene indicata dal riempimento in verde.
- Microphone – Apre il pannello di regolazione di proprietà del microfono.
Se Stop recog è abilitato allora durante la pronuncia delle frasi, delle conferme dei comandi e delle parole valide, il riconoscimento è disabilitato. Quindi prima di parlare si deve attendere che l’indicatore del segnale audio ritorni verde.
Note per le versioni
Versione 1.5: Questa è la prima versione pubblicata. La miglioreremo ma è già completa e usabile.
Versione 1.6
– Migliorato notevolmente il riconoscimento.
– Aggiunti i comandi “CMD_Prefix”, “CMD_FirstSlot”, “CMD_Confidence” e “CMD_RunSlot”.
– Reso evidente (con una barra rossa) che in alcuni momenti il riconoscimento è inattivo.
– Migliorato l’incolonnamento nella finestra di sinistra.
– Aggiunta la possibilità di scrivere commenti. I commenti devono iniziare con un singolo apice, un meno o un doppio slash, cioè ( ‘ ) , ( – ) oppure (//).
– Aggiunta la possibilità di scrivere nella finestra di sinistra (riconoscimento) anche dei campi con una o più “x” per indicare che lo Slot non va modificato.
– Introdotto uno”splitter” orizzontale che permette di minimizzare l’area dei linguaggi installati.
– Introdotto uno”splitter” verticale che separa le finestre di riconoscimento e pronuncia e che può essere spostato a destra e a sinistra.
– Aggiunto il pulsante “RUN” per avviare o fermare il riconoscimento.
– Aggiunta la possibilità di abilitare e disabilitare il “RUN” con un comando da Slot.
– Aggiunto oltre a “Load” che carica file di riconoscimento anche il comando “LoadTTS” che carica file di pronuncia.
Versione 1.7 – Aggiunto il comando “Pause” nel testo da pronunciare.
Versione 1.8 – Aumentato a 50 millisecondi il tempo di attivazione degli Slot quando si usa “pulse”. In questo modo non c’è il pericolo che le applicazioni controllate possano perdere l’impulso.
Versione 1.9 e 2.0 – Piccole correzioni.
Download di Theremino Voice – Versione 2.0
Theremino_Voice_V2.0
Theremino_Voice_V2.0_WithSources
Per tutti i sistemi Windows a 32 e 64 bit. Per Raspberry Pi, Linux, Android e OSX, leggere le note di installazione.
Questa applicazione è dedicata a chi non vede.
Il principio di funzionamento è innovativo (conversione diretta e istantanea dello spazio visuale nello spazio sonoro). Abbiamo controllato tutti i sistemi simili e nessuno ha mai fatto questo. Sarebbe quindi il caso di brevettarlo, ma noi faremo di meglio, lo pubblichiamo.
Una volta che una invenzione è pubblicata, nessuno può più brevettarla.
Gli uffici brevetti non accettano invenzioni che sono già di dominio pubblico.
L’algoritmo di conversione dello “Spazio Sonoro Equivalente”
Per i dettagli software, scaricare la applicazione e aprirla con Visual Studio 2008.
Per una spiegazione e un confronto con gli altri sistemi già esistenti, leggere questo documento:
EquivalentSoundSpace_ITA.pdf
Funzionamento
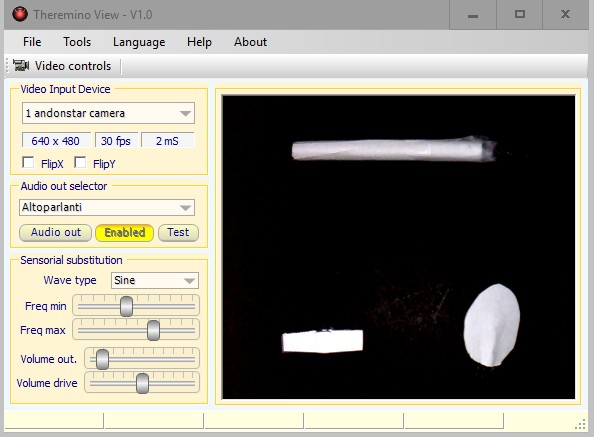
Occhiali con auricolari e telecamera (costano poco) e un Tablet in tasca.
Prestazioni
Una persona con la vista normale e con una benda, riesce a respingere una palla. Nessun sistema similare, esistente fino ad oggi, è così rapido.
Un non vedente, con l’udito molto sviluppato e un lungo periodo di allenamento, potrebbe raggiungere risultati impensabili. Forse anche giocare a ping pong.
Limiti della versione attuale
Nella versione 1.0 manca l’algoritmo di pre-trasformazione del video, che estrarrà solo le variazioni tra elementi adiacenti. Questo permetterà di riconoscere sia oggetti chiari su fondo scuro, che oggetti scuri su fondo chiaro. Con questa trasformazione le aree estese e di colore uniforme non produrranno suoni e il riconoscimento degli oggetti verrà facilitato.
La versione attuale non si adatta automaticamente alla luce e funziona bene solo con oggetti chiari su sfondo nero. Anche senza adattamento automatico si può ottenere un buon riconoscimento se la scena non è troppo complessa. Del resto anche i programmi simili, compreso il più usato The vOICe, non hanno l’adattamento automatico.
Pubblichiamo questa prima versione anche se è lontana dall’essere completa, per rendere “Arte nota” i concetti fondamentali e impedire che qualcuno li brevetti.
Download di Theremino View – Versione 1.0
Theremino_View_V1.0_WithSources
Per tutti i sistemi Windows a 32 e 64 bit. Per Raspberry Pi, Linux, Android e OSX, leggere le note di installazione.
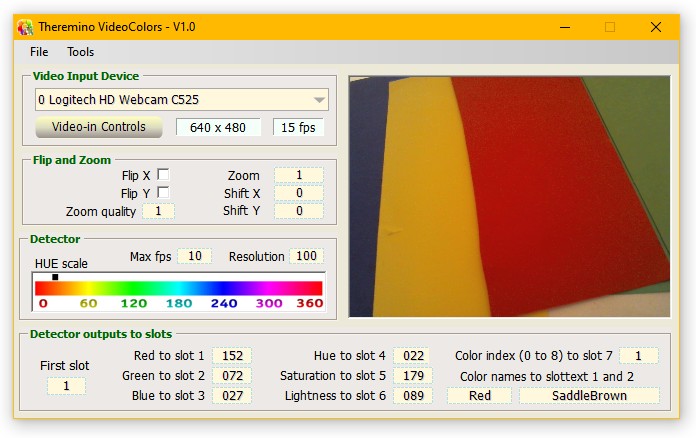
Questa applicazione decodifica i colori ed è notevolmente superiore ai sensori che si utilizzano con Arduino (ad esempio il TCS3200 e gli altri sensori simili). Il primo vantaggio è che si può vedere il colore da grande distanza, anche molti metri, mentre i sensori come il TCS3200 arrivano al massimo a una decina di millimetri. Inoltre regolando adeguatamente i parametri della telecamera si ottiene una stabilità di misura eccezionale. La tinta (HUE) misurata cambia pochissimo anche con livelli di illuminazione notevolmente diversi, sia quando l’immagine è molto scura che quando è chiarissima, quasi bianca.
Come sensore si utilizza una WebCam, scegliendola tra le più economiche. Una grande risoluzione (molti pixel) non serve a niente per questa applicazione per cui consigliamo di comprare le WebCam più economiche che riuscite a trovare. Eventualmente compratene due diverse e provate quale va meglio, perché non è possibile sapere come vanno senza provarle.
Come scegliere la parte di immagine da misurare
Il colore misurato è la media di tutti i pixel visibili per cui se si vuole selezionare una zona più piccola la si ingrandisce utilizzando i comandi Zoom e Shift.
Se si dispone del mouse al posto di utilizzare le caselle Zoom e Shift è meglio posizionare il cursore sulla immagine e utilizzare la rotella del mouse per ingrandire.
Impostazioni di velocità e qualità
Regolando le caselle “Zoom quality” e “Resolution” con numeri più alti si migliora leggermente la qualità di ingrandimento, ma si aumenta anche leggermente l’impegno della CPU.
Aumentando “Max fps” si ottiene una risposta più rapida alle variazioni di colore, ma si aumenta l’impegno della CPU. Un buon compromesso è il valore 10 che risponde in un decimo di secondo.
Significato dei valori che si misurano
I valori numerici vengono inviati sugli Slot numerici e i nomi dei colori vengono inviati sui TextSlot.
I valori misurati sono i seguenti:
R = Rosso (da 0 a 255)
G = Verde (da 0 a 255)
B = Blu (da 0 a 255)
H = Hue (da 0 a 360)
S = Saturation (da 0 a 255)
L = Luminosity (da 0 a 255)
Il valore “HUE” è la “tinta”, cioè il colore. Questa misurazione non tiene conto di luminosità e saturazione.
Il “ColorIndex” e la casella “Color name” di sinistra danno il più vicino tra i colori seguenti:
0=Nero 1=Rosso 2=Arancio 3=Giallo 4=Verde 5=Ciano 6=Blu 7=Viola 8=Bianco
La casella “Color name” di destra sceglie il colore più simile tra i colori di sistema.
I nomi dei colori vengono inviati a due SlotText (con indice che parte da First Slot”).
Le nuove applicazioni (primi mesi del 2022) utilizzano anche gli SlotText se ne hanno la necessità. Attualmente le altre applicazioni che utilizzano gli SlotText sono:
– Theremino_SlotTextToSpeech
– Theremino_Cobot
– Theremino_Automation
Note per le versioni
Versione 1.1 – I parametri modificati vengono salvati immediatamente nel file INI
Download di Theremino VideoColors – Versione 1.1
Theremino_VideoColors_V1.1
Theremino_VideoColors_V1.1_WithSources
Per tutti i sistemi Windows a 32 e 64 bit. Per Raspberry Pi, Linux, Android e OSX, leggere le note di installazione.
Theremino MindwaveBridge



Mindwave è un sensore di onde cerebrali prodotto da Neurosky. Si tratta del modello di sensore EEG più economico tra quelli attualmente presenti sul mercato. Se volete acquistarlo, Amazon lo vende a un prezzo più basso di quello del sito del produttore.
MindwaveBridge è un software che fa da ponte tra il Mindwave e il sistema Theremino e permette di utilizzare tutti i dati in arrivo dal sensore (attention, meditation e le bande di frequenza), disponibili su slot configurabili a piacere.
L’immagine del Theremino Master vicino al Mindwave è solo indicativa. Per mandare i dati da mindwave ad altri software del sistema (ad esempio il sintetizzatore Theremin) il Master non è necessario ma basta il software “Theremino Mindwave Bridge” che è gratuito.
Nelle nostre prove abbiamo inviato i dati Raw al Theremino SoundPlayer, per emettere suoni campionati, modulati in frequenza dalle onde mentali. Ma questo software apre la strada a ogni genere di esperimenti, limitati solo dalla fantasia. Per esempio si potrebbe usare ThereminoScript per muovere motori su comandi mentali o accendere led per la cromoterapia e l’induzione di un feedback di rilassamento…
ATTENZIONE:
Prima di pensare di usare la mente per comandare operazioni complesse,
tenete conto dei limiti di questa tecnologia.
Leggete questa pagina: https://www.theremino.com/blog/biometry
Download di Theremino Mindwave Bridge – Versione 1.6
Theremino_MindwaveBridge_V1.6
Theremino_MindwaveBridge_V1.6_WithSources
Per tutti i sistemi da Windows XP a Windows 10, sia 32 che a 64 bit (Linux e OSX con Wine)
– – – – – – – – –
![]()
![]()
![]() Documentazione editabile in formato ODT – Italiano, Inglese e Giapponese
Documentazione editabile in formato ODT – Italiano, Inglese e Giapponese
Chi conosce bene queste lingue potrebbe aprire i file con Open Office, correggerli e inviarceli. Per le altre lingue potete prendere il file inglese e farlo tradurre da: onlinedoctranslator che è ottimo, velocissimo e rispetta la formattazione.
MindwaveBridge_Documentation_ITA_ENG_JAP
– – – – – – – – –
Consigli per chi pensa di acquistare un MindWave
Questa è la versione usata nelle prove : Mindwave Bluetooth – Amazon
Prezzo Amazon: 110 Euro circa (108 Euro + Adattatore Bletooth)
Prezzo Amazon: 78 Euro tutto compreso (anche spese di spedizione)
Conviene comprarli da Amazon, sul sito del produttore il prezzo è maggiore di qualche euro.
http://store.neurosky.com
http://store.neurosky.com/products/mindwave-1
http://store.neurosky.com/products/mindwave-mobile
Theremino EmotionMeter – Versione 3.1
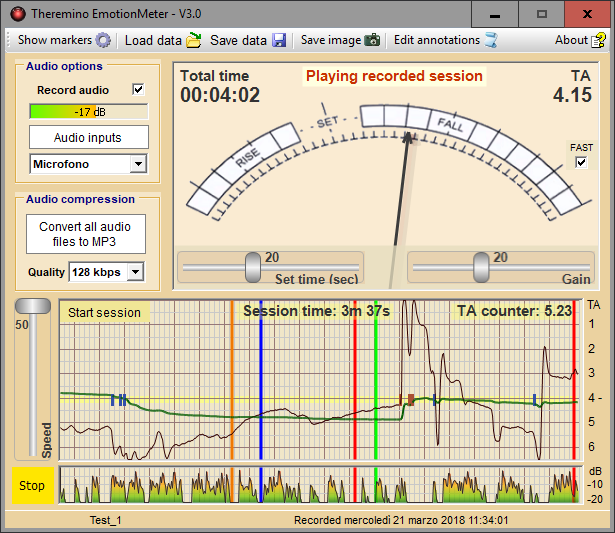
Questo è un apparecchio facile da costruire e davvero interessante. Si ottengono prestazioni migliori dei costosi$$imi e-Meter, ma usando il minimo hardware possibile, per aumentare la affidabilità e diminuire i costi.
Ci teniamo a precisare che si tratta solo di esperimenti di rilevazione di parametri biologici. Non stiamo dando credito alle idee (a volte anche pericolose) che vengono diffuse da alcune sette pseudo-scientifiche.

Questa immagine mostra un e-Meter costruito con componenti discreti (transistor e integrati). Sono apparecchi costosi (da 300 a 5000 dollari), ma la loro progettazione è rozza, come evidenziato su wikipedia e confermato da numerosi siti, ad esempio questo (o in inglese questo) e anche questo oppure questo.
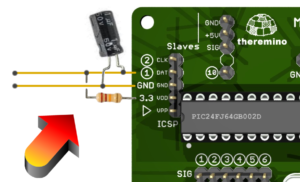
Con la nostra versione si elimina il 99% dell’hardware, i due componenti indicati dalla freccia sono tutto quello che serve per costruire un completo e-Meter. Sono componenti comuni che tutti hanno nel cassetto, si collegano in cinque minuti e si spende poco più di dieci Euro, modulo Master compreso.
La nostra versione è completamente digitale, quindi è più precisa degli apparecchi originali e ha prestazioni uniche.
Si può registrare la sessione, audio compreso, per rivederla nei particolari in seguito. Si possono utilizzare i comandi vocali, nonché collegare altri apparecchi che ripetono lo stesso segnale. Sono disponibili tre modi di funzionamento, quello originale, un azzeramento automatico e un metodo innovativo che utilizza la derivata del segnale. Leggete la documentazione seguente, che spiega tutto su questo apparecchio.
Download della documentazione
![]() File di documentazione in italiano
File di documentazione in italiano
EmotionMeter_Application_ITA.pdf
EmotionMeter_Hardware_ITA.pdf
EmotionMeter_History_ITA.pdf
![]() English documentation files
English documentation files
EmotionMeter_Application_ENG.pdf
EmotionMeter_Hardware_ENG.pdf
EmotionMeter_History_ENG.pdf
![]()
![]() Documenti originali in formato ODT
Documenti originali in formato ODT
EmotionMeter_Original_OpenOffice_Docs.zip
Download di Theremino EmotionMeter – Versione 3.1
Theremino_EmotionMeter_V3.1
Theremino_EmotionMeter_V3.1_WithSources
Per tutti i sistemi da Windows XP a Windows 10, sia 32 che a 64 bit (Linux e OSX con Wine)
Elettrodi Attivi




Gli elettrodi attivi sono applicabili sulla pelle anche senza gel. Grazie alla loro impedenza di ingresso quasi infinita e alla loro costruzione innovativa, la captazione dei disturbi a frequenza di rete è minima. Diventano quindi possibili configurazioni anche senza elettrodo di riferimento. Tutta l’elaborazione viene fatta in software riducendo quindi il costo dell’hardware quasi a zero. Il numero di sensori collegabili è variabile, si può iniziare con un solo sensore e usarlo per ECG e EEG indifferentemente. Poi si possono aggiungere sensori in numero illimitato (6 direttamente al ThereminoMaster e 8 ad ogni “Slave” aggiuntivo)
La ricerca sugli elettrodi attivi ha sviluppi inattesi, prima ancora di averli finiti siamo passati a un diverso metodo, gli elettrodi senza contatto. Per lasciare più posto ai nuovi sviluppi abbiamo spostato tutto in una sezione del BLOG: blog/biometry
Theremino EEG
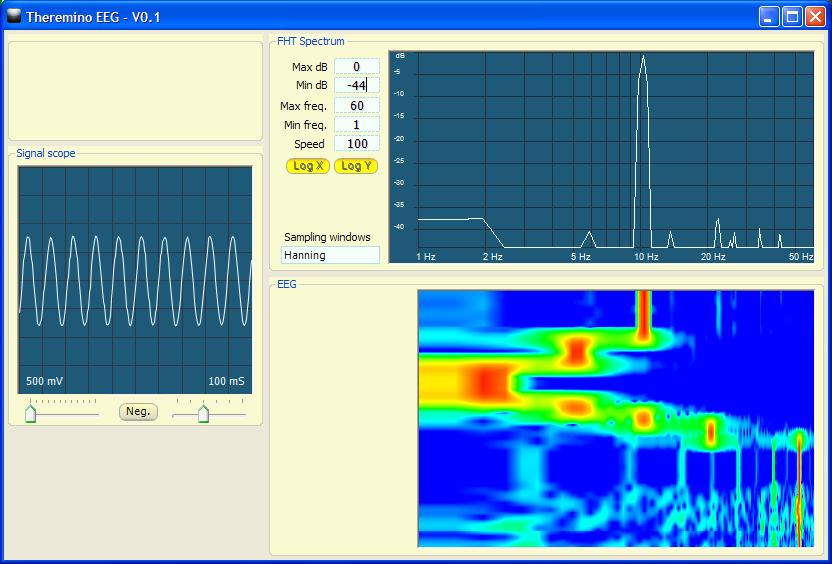
Questa è la prima versione della applicazione EEG, per i primi test sui sensori EEG e ECG. Molte parti saranno da migliorare. Il software è semplice e i sorgenti sono disponibili. Quindi se qualcuno vuole proseguire il lavoro è il benvenuto.
Ulteriori informazioni in queste pagine:
https://www.theremino.com/blog/biometry
https://www.theremino.com/hardware/inputs/biometry-sensors
– – – – – – –
Download di Theremino EEG – Versione 1.3
Theremino_EEG_V1.3.zip
Theremino_EEG_V1.3_WithSources.zip
Per tutti i sistemi da Windows XP a Windows 10, sia 32 che a 64 bit (Linux e OSX con Wine)
Programma delle ricerche

Tensione cutanea
- Elettroencefalografia
- Elettrocardiografia
- Elettromiografia
Resistenza cutanea
- E-meter
- Macchine della verità
- Ricerca dei punti dell’agopuntura
Posizione del corpo
- Sensori capacitivi a lunga distanza (CapSensorHQ)
- Sensori capacitivi a breve distanza (Cap Keys)
Parametri cardiocircolatori
- Saturazione (pulsiossimetro)
- Curva plestimografica
Il referente per la biometria è il nostro nuovo collaboratore Maurizio.
![]() Maurizio è un GhostBuster senior. In italiano: “Esperto acchiappa fantasmi”. Incidentalmente: il film GhostBusters è circa al suo quarantesimo anniversario e nel 2023 dovrebbe uscire la quarta versione.
Maurizio è un GhostBuster senior. In italiano: “Esperto acchiappa fantasmi”. Incidentalmente: il film GhostBusters è circa al suo quarantesimo anniversario e nel 2023 dovrebbe uscire la quarta versione.
Si tratta di misurare anche l’imponderabile. Non fatevi ingannare da queste immagini, ci scherziamo un po’ sopra ma sono ricerche serie.